
 Simon Edel
Simon Edel
Über Hype, Fails und sinnvolle Use Cases von künstlicher Intelligenz im Marketing
Nicht erst seit ChatGPT ist künstliche Intelligenz im Marketing in aller Munde. KI-generierte Videos, Bilder und Texte begegnen uns überall – in Social Media, Webshops und mehr. Der Hype hält an, und große wie auch kleine Software-Hersteller setzen in ihren Produkten auf KI-Funktionen, wo es nur geht. Fast panikartig scheinen Tech-Konzerne auf der Suche nach sinnvollen Use-Cases zu sein – was dafür spricht, dass es über die wenigen offensichtlichen hinaus gar nicht so viele gibt. Auf die Welle der Begeisterung folgt nun die Welle der Kritik. Und mit diesem Beitrag der Versuch, dazwischen den „State of the Art“ zu identifizieren.
Künstliche Intelligenz im Marketing und ihre Grenzen: Fails und typische Kritik

Menschen mit zu vielen Gliedmaßen, alptraumhafte Bildlandschaften und Suchmaschinen, die Pizza mit Klebstoff empfehlen oder erklären, dass der Erfinder des „Backflips“, John Backflip, im Jahr 1316 verbannt wurde, weil er von seinem Rivalen William Frontflip der Hexerei bezichtigt wurde: das Internet ist voll mit KI-Fails.
Das ist häufig sehr amüsant. Gleichzeitig fragt man sich aber schon, ob jemand die KI-Produkte überhaupt getestet hat, bevor sie live gingen. Klar ist: Vieles davon wird sich durch Weiterentwicklungen erledigen. Das Problem der Gliedmaßen etwa ist mittlerweile deutlich weniger präsent, und Unternehmen setzen alles daran, die Imageschäden durch „Fails“ zu minimieren. KI aufgrund dieser Art der Probleme als sinnlos abzutun ist daher oberflächlich und falsch.
Sinnvolle Use Cases für künstliche Intelligenz im Marketing
Denn es gibt sie, die sinnvollen Use Cases für KI. Nicht nur in der Medizin, der Versicherungsbranche und anderen zahlengetriebenen Wirtschaftszweigen, sondern auch im Marketing.
Natural Language Generation (NLG) etwa automatisiert die Erstellung von Texten. Aus technischen Daten entstehen Produktbeschreibungen verschiedener Tonalität und Länge, Kampagnentexte und komplette Marketingartikel, und das auf Knopfdruck (Texter hassen diesen Trick!). Und das mehrsprachig, in Sekundenschnelle – denn die Large Language Models (LLM) wurden ursprünglich für Übersetzungen entwickelt.
Im Bereich der Produktdatenqualität bzw. im Datenmanagement lassen sich per KI Produkte anhand ihrer technischen Eigenschaften kategorisieren, digitale Assets wie Bilder und Videos mit den passenden Begriffen taggen, das gesprochene Wort als Text extrahieren oder auch die Qualität verschriftlichter Texte überprüfen. Tonalität passend, Sprachregeln eingehalten? Auch das Einkürzen von Texten ist ein gängiger Case – wobei sich gerade bei den letzten beiden Cases herauskristallisiert, dass die KI noch deutlich schlechter performt, als allgemein angenommen. Aber dazu später mehr.
Personalisierung war neben der Textgenerierung das Steckenpferd für KI im Marketing. Von Produktempfehlungen, der Ableitung von Vorlieben bis hin zur Erkennung und Berücksichtigung von Kontext wird KI überall eingesetzt. Wo befindet sich der Kunde, und in welchem Stadium seinen Kaufvorgangs? Informiert er sich nur, oder wird es schon konkret? Auch das schnelle Erkennen auftretender Trends anhand aktueller Such-, Bewegungs- und Kaufdaten ist häufiger Anwendungsfall, funktioniert aber nur bei hinreichend großer Datenmenge. Entweder ist man selbst ausreichend großer Player, oder schließt sich über Plattformen mit anderen Händlern zusammen – und unterstützt damit auch den Wettbewerb.
Auch in der Suche kann KI durchaus hilfreich sein und die Auffindbarkeit von Produkten, Bildern und Videos erheblich verbessern, indem nicht nur nach dem gesucht wird, was der Benutzer eingibt, sondern auch nach inhaltlich ähnlichen Formulierungen. Automatisch getaggte Bilder und transkribierte Videos sind sowieso deutlich einfacher zu finden.

Erwartungen und Realität
Leider werden durch den ständigen Hype und die Geheimnistuerei um die Funktionsweise völlig unrealistische Erwartungshaltungen geweckt. In Wahrheit ist keines der KI-Produkte auf dem Markt intelligent im Sinne menschlicher Intelligenz. Es gibt keine starke KI (Künstliche Allgemeine Intelligenz), und es gibt derzeit auch nichts, das nur ansatzweise in die Nähe „echter“ Intelligenz käme. Das geht schon damit los, dass darüber Uneinigkeit herrscht, was Intelligenz überhaupt ist. Wenn jemand behauptet, seine KI-Modelle stünden kurz vor dem Übergang zu starker KI, sammelt diese Person in der Regel gerade Gelder für die nächste Finanzierungsrunde oder den Börsengang.
In der Praxis reden wir von Generativer KI, Machine Learning / Deep Learning und Computer Vision. Anders formuliert: Es geht um Wissensbasierte Systeme bzw. Expertensysteme, die Informationen mathematisch aufbereiten und zur Abfrage durch Menschen oder Maschinen bereitstellen. Es geht um Musteranalysen und Mustererkennung in mehr oder minder großen Datenmengen, und um Mustervorhersage anhand dieser Analysen. Nichts davon klingt ansatzweise nach selbstständigem Denken, geschweige denn Intelligenz? Ganz genau. Das ist der Punkt.
Ist ChatGPT „bullshit“?
Mustervorhersage ist ein gutes Beispiel für falsche Vorstellungen darüber, was KI kann und was nicht. Large Language Models wie ChatGPT besitzen weder Wissen noch Verständnis. Sie generieren lediglich statistische Wortketten. GPT benutzt den Prompt, um auf einer Art Landkarte einen Startpunkt festzulegen, und von dort aus die Worte aneinanderzureihen, die von dort aus gesehen am wahrscheinlichsten hintereinander passen. Landet man in einem Teil der Landkarte, in dem das Modell besser trainiert wurde, ergeben die Antworten häufig Sinn. Landet man in eher dünn besiedeltem Gebiet, ist das Ergebnis klassischer Bullshit im Sinne von Harry Frankfurt (vgl: „ChatGPT is bullshit“).
Daher kristallisiert sich im Moment heraus, dass insbesondere Textkürzungen und inhaltliche Prüfungen mit LLM deutlich schlechter funktionieren, als es auf den ersten Blick scheint. Den Modellen fehlt das inhaltliche Verständnis der Texte, die sie prüfen sollen. Sie mögen kürzen, aber entstellen regelmäßig den Sinn, lassen Schlüsselpassagen weg und betonen unwichtige Nebensachen. (siehe z.B. ASIC-Report vom 21.05.2024).
KI-Modelle sind Mathematik, keine Zauberei. Sie verhalten sich ihrem Training entsprechend. Man füttert eine KI mit den Bewerberdaten der letzten Jahre und sagt ihr, welche der Bewerber man eingestellt hat, damit sie beim Selektieren künftiger Bewerber hilft. Wurden vorzugsweise mittelalte weiße Männer mit Informatik-Bachelor eingestellt? Rate mal, welche Bewerber die KI dann vorschlägt. Man kippt die Daten aus der Verbundkaufanalyse in ein KI-Modell? Die KI macht Verbundkaufanalyse.
Grundsätzlich gilt: wenn man eine KI mit Daten trainiert, bei denen Menschen nach einem stumpfen Algorithmus vorgegangen sind, wird die KI sich auch so verhalten. Sie manifestiert die Vorurteile und Einschränkungen aus den Trainingsdaten und zementiert damit das Verhalten, mit dem sie trainiert wurde. Deswegen sind Daten für künstliche Intelligenz besonders wichtig.
Die Sache mit den Daten
Ohne Daten geht es also nicht, aber mehr Daten machen es nicht unbedingt besser; auch wegen der angesprochenen Lücken und dem Bias, der Voreingenommenheit, die Daten ausnahmslos enthalten. Außerdem wissen wir mit diesen Daten offensichtlich deutlich weniger anzufangen, als es die Hersteller entsprechender Lösungen suggerieren.
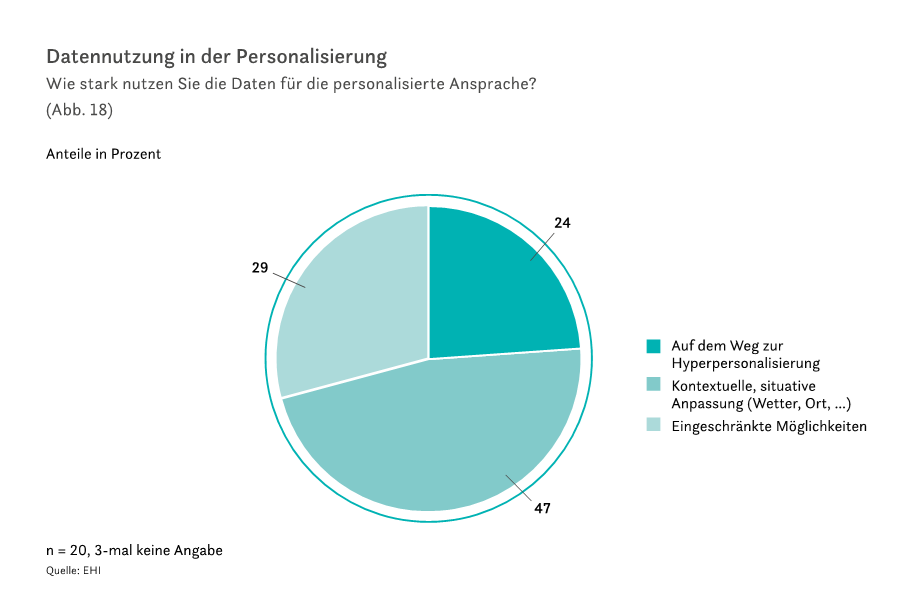
Mehr Daten lösen das Dilemma augenscheinlich nicht. Es gibt ein komplettes globales Ökosystem riesiger Anbieter, die auf mehr oder weniger legalem Wege jeden Schritt der Kunden zu erfassen und zu analysieren versuchen. Die erhobenen Datenmengen sind unvorstellbar groß und wachsen exponentiell. Wie gut hilft das beispielsweise dem Handel in Deutschland, die Kunden personalisiert anzusprechen?
Das EHI Retail Institute forscht hierzu regelmäßig. Im EHI-Marketingmonitor Handel 2023-2026 können wir nachlesen: 29% des Handels können gar nicht oder schlecht personalisieren. Weitere 24% nutzen Recommendation Engines und einfache Segmentierung. Und erstaunliche 47% versuchen erst gar keine 1:1-Ansprache des einzelnen Kunden, sondern weichen komplett auf Kontext wie Ort und Wetter aus, um zu segmentieren. Also in Summe: 76% des Handels in Deutschland personalisieren kaum oder schlecht.
Das liegt nicht daran, dass zu wenig Daten gesammelt werden. Wir alle kennen die Cookie-Banner: „Wir und unsere 1504 Partner schätzen Ihre Privatsphäre“. (Ich wünschte, die Zahl wäre ausgedacht.) Von „legitimem Interesse“ wollen wir gar nicht erst anfangen. Das halten etwa 50% der Internet-Nutzer offensichtlich für alles andere als legitim und verwenden Adblocker, um Werbung und Cookies zu blockieren. Die Datensammelei findet die überwiegende Zahl der Kunden so unangemessen, dass Apple bei seiner Kundschaft damit zu punkten versucht, dass selbst „zugestimmte“ Cookies automatisch spätestens alle zwei Wochen gelöscht werden. Gleichzeitig hat Google die Ablösung der 3rd-Party-Cookies, die dieses Jahr stattfinden sollte, nun doch wieder abgesagt, weil besagtes Datensammel-Ökosystem noch nicht bereit war, diese Datenquelle aufzugeben.
Daten nutzen oder Münze werfen?
Und wie nützlich sind diese ganzen Daten jetzt, um gezielt die richtigen Kunden anzusprechen? Das wollte eine Studie zur Effizienz bei der Erreichung des „richtigen“ Kunden des MIT und der Melbourne Business School herausfinden (vgl. „Is first- or third-party audience data more effective for reaching the ‚right‘ customers? The case of IT decision-makers“)

In der Studie wurde mit globalen 3rd-Party-Datenbrokern gearbeitet, deren Kerngeschäft es ist, Daten zu sammeln und daraus eine möglichst präzise Kundensicht abzulösen. Angesprochen werden sollten IT-Entscheider. Es stellte sich allerdings heraus, dass nur 14,3% der angeblichen IT-Entscheider tatsächlich welche waren – bei 85,7% war die Selektion also falsch. Noch schlechter wurde es, wenn man stattdessen nach Senior-IT-Entscheidern suchte – hier waren nur noch 7,5% der Empfänger tatsächlich korrekt, eine Versagerquote von 92,5%.
Selbst wenn man auf grundsätzlichste Kundensicht geht und beispielsweise das Geschlecht anschaut, wird es nicht besser: Das Geschlecht war nur in 42,3% der Fälle korrekt. Selbst ein Münzwurf ist präziser als das – und die Studie behandelt Gender strikt binär, obwohl das Spektrum größer ist.
3rd-Party-Daten dürften bei solcher „Performance“ weder derzeit noch in der Zukunft auf eine sinnvolle Sicht auf den Kunden führen. Dieser Kaiser ist völlig nackt.
Was lässt sich aus Daten überhaupt ablesen?
Was kann man daraus ablesen, wenn man trackt, dass ich vier Sekunden lang ein Video angesehen habe, bevor ich die Produktseite verlassen habe? Oder daraus, wie viele Likes ein Post auf LinkedIn generiert hat? Engagement heißt erst einmal nur, dass jemand interagiert hat. Das höchste Engagement bekommen Click- und Flamebait, oder sachlich falsche Inhalte. Engagement misst aber letztlich nur den „Erregungsgrad“. Wenn wir über Werbung in Social Media sprechen, dann gilt natürlich: mehr Engagement ist besser. Aber sobald ich wirklich Erkenntnisse gewinnen möchte, die mir Optimierung erlauben, muss ich viel tiefer einsteigen und das Warum ergründen. Ich muss Ursache und Wirkung richtig zuordnen, um wirksamer zu sein.
Kein Problem mit KI? Natürlich ist KI herausragend darin, Korrelationen zu erkennen. Das hilft aber nichts, wenn man Korrelation nicht von Kausalität unterscheiden kann, sprich: ob es sich um Zufall handelt, oder um Ursache und Wirkung – und was die Ursache ist und was die Wirkung. Beispiel gefällig?
Wenn man sich die statistische Beziehung zwischen der Größe eines Feuers anschaut (gemessen in Schadenssumme in Euro) und der Anzahl der eingesetzten Feuerwehrleute, wird man feststellen, dass die Schadenssumme höher wird, je mehr Feuerwehrleute vor Ort waren. Logischer Schluss: Wir müssen die Feuerwehr abschaffen, dann gibt es auch keine großen Feuer mehr, denn je weniger Feuerwehrleute, umso weniger Schaden.
Die Frage nach Kausalität und Korrelation kann man nur beantworten, wenn man sich mit der Materie auskennt, um die es in den Daten geht. Wenn man Domänenwissen hat, wie IT-Menschen und Berater es auch nennen. KI hat kein Domänenwissen und keine Intelligenz, KI ist Modell gewordene Mathematik, die gut darin ist, Muster zu finden. Interpretieren muss sie der Mensch, zumindest noch für die absehbare Zukunft.
KI verstehen heißt, KI besser anwenden
Nun könnte der Eindruck entstehen, ich wollte von KI abraten. Aber das Gegenteil ist der Fall! Wenn man die prinzipbedingten Grenzen und Möglichkeiten der verschiedenen Arten von KI versteht, gibt es jede Menge Chancen auszuloten. Was könnten Use Cases in der eigenen Organisation sein? Wo bietet KI uns Einsichten, die anders nicht zu erhalten sind? Wo ist KI effizienter als die zurzeit eingesetzten Algorithmen? Und ist die bessere Performance auch nützlich und wirtschaftlich, oder fressen die höhere Komplexität und der höhere Aufwand die Effizienzgewinne wieder auf? Gerade Letzteres wird im Zuge von FOMO und Hype im Moment zu selten betrachtet.
Lass dir KI nicht ausreden. Teste sie mit einem Piloten oder einem Proof of Concept. Rechne deinen Business Case durch, lass dich beraten, und mach dich auf den Weg, am besten mit einem Partner auf Augenhöhe. Wir wüssten da wen… 😉
